
Seminar
This is the note taken in Wharton Statistics seminar, FOLDS Seminar (Optimization & Learning), ASSET Seminar (Safety), Theory seminar and external seminars. It is mainly for writing down things / resources that I learn from the seminars, and they are not guaranteed to be comprehensive or accurate.
Statistics Seminar (Sep 3rd 2025)
Speaker: Aaditya Ramdas, CMU
Title: The Numeraire e-variable and Reverse Information Projection
Jonathan Li (Barron’s student at Yale Stats)’s PhD Thesis on Estimation of Mixture models
Information Projection: Projecting a probability distribution $q$ onto a set of distribution $P$.
Other areas that have relationships with gambling:
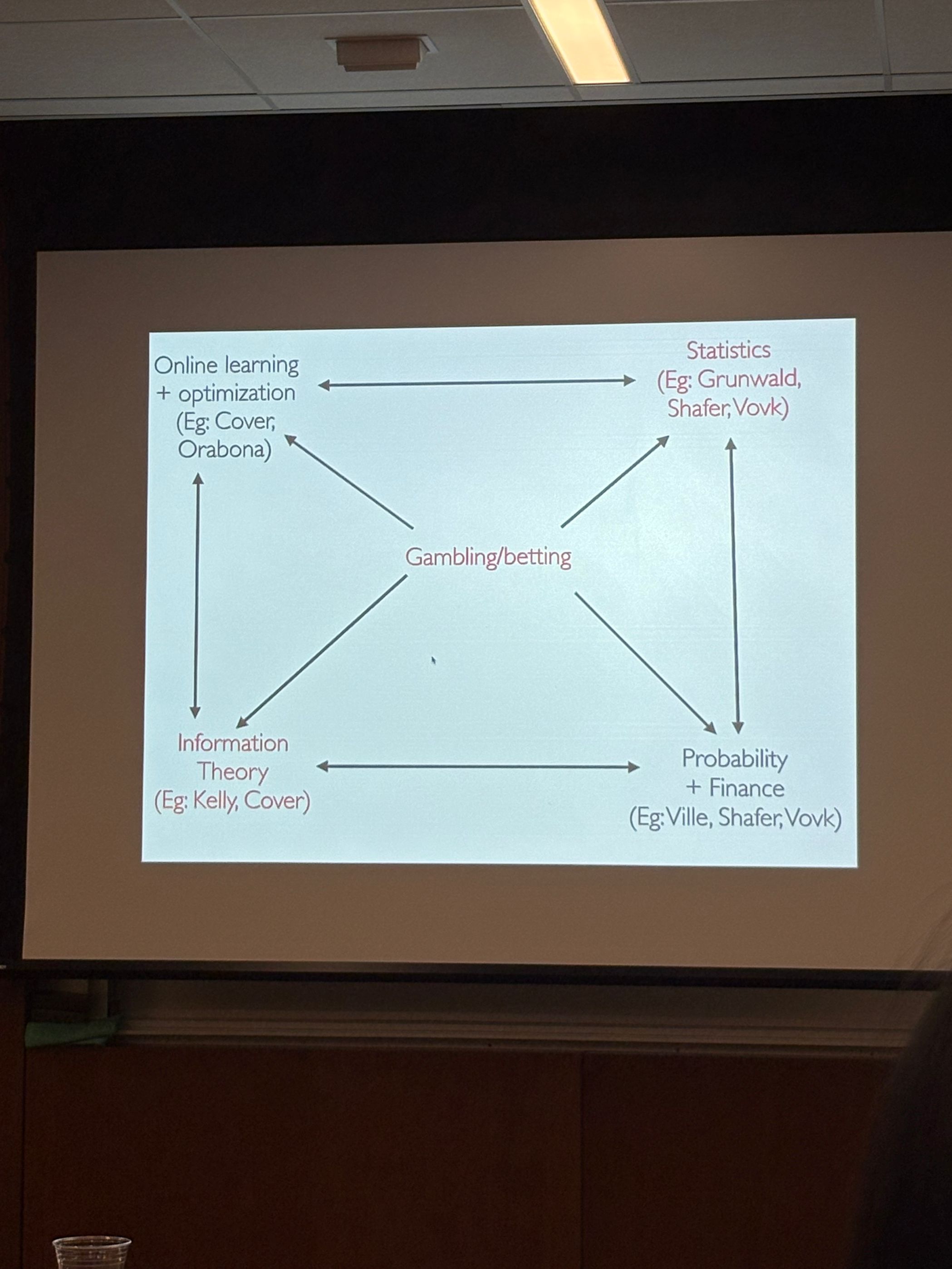
Many people here I haven’t heard about, need to research later.
Useful / Latest Online learning lecture note
Classical works on bets: A New Interpretation of Information Rate, Optimal gambling systems for favorable games.
FOLDS Seminar (Sep 4th 2025)
Speaker: Joel Tropp, Caltech
Title: Positive random walks and positive-semidefinite random matrices
Paper: https://arxiv.org/abs/2501.16578
If we consider (normalized) positive random walk on the real line, i.e. $W \geq 0$, and $\mathbb{E}[W^2] < + \infty$. We consider the random walk $Y = \frac{1}{n} W_i$ where $W_i \sim W$ and $\mathbb{E}[Y] = \mathbb{E}[W]$.
To have $Y \gg \mathbb{E}[Y]$ need to exist one large step $W_i$, to have $Y \ll \mathbb{E}[Y]$ then we need to have all steps $W_i$ small. Therefore the right tail would look heavy-tail i.e. $\sim (nt)^{-2}$, and left tail behaves like light tail i.e. have exponential rate $e^{-nt^2}$.
We are able to show that the left tail has subGaussian behavior and can be approximately characterized by a Gaussian $Z \sim \mathcal{N}( \mathbb{E}W, \frac{1}{n} \mathbb{E}W^2)$ using Paley–Zygmund inequality (Kind of second moment method).
Then we extend the discussions to PSD matrices $W_i$, we are curious about lower bounds of $\lambda_{\min}(Y)$, which describes (quantitative) injectivity. We can write it as
\[\lambda_{\text{min}}(Y) = \min_{\| u \|_2 = 1} \frac{1}{n} \sum_{i=1}^n u^\top W_i u.\]where the inside term is the “positive random walk” which hates to be zero, and the outside is to find the “worst direction” to minimize the term.
Here, the useful thing to deal with high-dimensional Gaussian is that, if we are dealing with symmetric $d \times d$ matrix $Z$, then it is Gaussian iff $\text{Tr}[MZ] $ is real Gaussian for each $M$ which is a $d \times d$ symmetric matrix.
Would be able to establish the Gaussian comparison i.e. $\lambda_{\min}$ of $Y$ and Gaussian $Z$, with some correction term (2.4 in Paper). An important application of this paper is the sparse random vector. It may also have applications in dimension reduction.
https://arxiv.org/pdf/2012.11654 might related to lowest eienvalue of NTK also?
FAI Seminar (Sep 4th 2025)
Speaker: Siyu Chen, Yale
Title: Polysemanticity in language models
Paper: https://arxiv.org/abs/2506.14002
Superposition: # Representated features $\gg$ embedding dimension.
Polysemantic neurons - activating for many concepts.
Drawback of previous methods:
- L1 regularization: activation shrinkage (When L2 loss is small to some degree, L1 regularization would dominate the loss)
- TopK: Sensitive to randomness and inconsistent in feature recovery.
Synthetic setup: 
This paper uses theory to classify different superposition regime and finds SAE can learn feature while activation frequency $p = O(s/n)$ where $s$ stands for data sparsity and $n$ is total number of features.
Idea of this paper: Use different sets of biases to “resonate” with different frequencies of features in data.
Training dynamics theory idea: Overparametrization ensures there exists some neuron at initialization aligns better with the signal. Then we decompose the signal and noise, and shows that after iterations it would turn to learning the signal.
Follow-up work on transcoder. This paper worths diving into later.
Theory Seminar (Sep 5th 2025)
Speaker: Tomer Ezra, Harvard
Title: Algorithmic Contract Design
Contract Theory. Have Principal and Agent, want: Find contract that max. the principal’s utility.
Principal-Agent Contract Model [Ross’73]; Combinatorial Contract Model [DEFK’21];
Complement-free Hierarchy [LLN’06] https://chatgpt.com/share/68bb15d9-23d0-800c-8f22-e13bd14b3c75
Single-agent [FOCS’ 21], multi-agent [STOC’ 23] + [SODA’ 25]
Classical paper https://arxiv.org/abs/cs/0202015
ASSETS Seminar (Sep 10th 2025)
Speaker: Furong Huang, Maryland
Title: Rethinking Test-Time Thinking: From Token-Level Rewards to Robust Generative Agents
Test-time alignment.
GenARM: Use autoregressive reward model (more efficient than trajectory-level RM). Have weak-to-strong guidance. Can align with multiple human objects without retraining. Similar to Model predictive control in terms of intuition.
Thinklite-VL: Run MCTS and calibrate the problem difficulty as # of iterations. Use curriculum learning.
MORSE-500: Programmatically controllable benchmark to stress test multimodel reasoning. Reasoning simulator that provides infinite training data for next-gen AI.
Does Thinking More always Help? (Figure 2): Interesting to see the accuracy drops after overthinking. Gaussian modelling of policy and reward functions. Related: The illusion of thinking, the illusion of illusion of thinking.
Adaptive, runtime defense against dynamical adversarial strategies. AegisLLM.
FOLDS Seminar (Sep 11th 2025)
Speaker: Rina Barber, UChicago
Title: Algorithmic stability for regression and classification
Distribution-free setting (weaker assumption). Hard to prove concentration but can prove a milder condition - stability (perturbaton to / resample a small fraction of training set).
Verify algorithmic stability in practice. Hardness result: “Black box tests for algorithmic stability”, “Is algorithmic stability testable”.
Convert algorithms to stable algorithm.
Algo Stability for classification: Two-stage learning process.
Conformal prediction textbook: https://arxiv.org/pdf/2411.11824
Theory Seminar (Sep 12th 2025)
Speaker: Yuhao Li, Columbia
Title: Query Complexity of Tarski Fixed Points
Want: Find arbitrary fixed point in the lattice structure, find algo with complexity poly(d, log N) instead of O(dN). This fixed point is useful in PL, database, game theory and economics.
The Parity Game problem sounds interesting.
“Deciding parity games in quasipolynomial time. STOC 2017 Best Paper.”
https://arxiv.org/abs/2005.09836 Upper Bound $O(log^d n)$ by using binary search to find fixed point
Exist $O(log^2 N)$ algo for $d = 3$.
UP is the class of decision problems solvable by a nondeterministic polynomial-time Turing machine such that for every input, there is at most one accepting computation path. Factorizaton is in $\text{UP} \ \cap \text{Co-UP} $.
ASSETS Seminar (Sep 17th 2025)
Speaker: Guy Van den Broeck, UCLA
Title: Symbolic Reasoning in the age of LLM
Ctrl-G: Adaptive logical control for LLM. NeurIPS 2024. https://arxiv.org/pdf/2406.13892
Use tractable circuit model (like HMM) distilled from the transformer LLM (Digital twin that can do symbolic reasoning). Constraints are represented as DFAs and refine LLM outputs during inference time.
Using circuits which can be scaled up and expressive compared with GPT and diffusion model, yet interpretable and can do probabilistic reasoning.
Pyjuice: Scaling Tractable Probabilistic Circuits: A Systems Perspective https://arxiv.org/abs/2406.00766.
ASSETS Seminar (Sep 24th 2025)
Speaker: Yiqiao Zhong, UWM
Title: How does LLM generalize in OOD Task, insights from model’s internal representations
Generalization, Geometry, Emergence.
Copying Task Setting. OOD Data: Token distribution changes from power law to uniform, change length of repeated segment changed from [10, …, 19] to [25].
Two-layer TF (Attn only) generalizes OOD, one-layer TF fails to generalize. (Rule-learning and weak learning phase).
What compositional structure enables copying: alignment of First-layer OV circuit and second-layer QK circuit. Compute diagonal score measures normalized average diagonal entries of the product. Also have subspace matching: generalized cosine similarity between two principled subspaces. The transition aligns with the emergence phenomenon.
Generalize from two layers to multiple layers. Bridge subspace: \(\mathcal{V} = \text{span}(W_{OV,j}) = \text{span}(W_{QK,k})\) This generalizes the linear representation hypothesis.
This is one examples of rule subspace (besides concept subspace), might be other subspaces for other skills, like CoT.
GRASP Seminar (Sep 24th 2025)
Speaker: Deepti Ghadiyaram, Boston University
Title: Interpretable and Leveraging Diffusion Representations
Goal: Study the semantic information component in generative models. Use k-sparse autoencoder. => Get diffusion features Consider U-Net, train k-SAE in different layers. More layers up the features extracted are more coarse. Takeaway: Different layers capture different levels of information. Can also do non-linear probing.
Diffusion features benefit reasoning tasks.
Wharton Stats Seminar (Oct 1st 2025)
Speaker: Michael Jordan
Title: A Collectivist, Economic, and Statistical Perspective on AI
Interaction with LLM can be trated as interacting with a huge collective of experts. LLM fails to do uncertainty quantification.
Information assymetry and uncertainty in interaction in groups.
Problems in Stats/CS/Econ Interface:
- Relationships among optima, equillibria, and dynamics in high dim.
- Information assymetries, contract and stat inference
- UQ for black-box adversarial setting
- Bias mitigation and decision-making
- Recommendation systems with incentives
- Implications for regulation and governance of adaptive mechanism design
Market: equillibria, reduced uncertainty.
Three-layer data markets. Users <-> Platform <-> Data Buyer. Data is good/service/mechanism.
“Inverse problem” of game theory. Inverse problem of Nash equillibrium and option.
Statistical Contract Theory Principal-agent model
FLANN Seminar (Oct 6th 2025)
Speaker: Kaiyue Wen Title: Transformer are not interpretable via myopic methods
Attention Map -> Syntactic trees (Rogers et al. 20) Can be misleading, some of the heads interpretable some are not. Turning off both respectively has similar effects.
Q: Can we reliable interpret algorithms by looking at individual components. Individual: Attention Patterns, Single Weight Components. A: May not, using Dyck Language to provide a toy example.
Dyck: The language of balanced parentheses. Use stack-like algorithm to solve.
Prior work: TF learn dyck with highly stack-like attention patterns, predict on the last unclosed bracket. Their results: TF learns diverse attention patterns on Dyck.
Training data has Bounded depth (TF cannot learn unbounded depth). Theory on squared loss, or CE with smoothed labelling, cannnot directly analyze CE.
Attention Matrix:
Minimal first layer: Output only depends on bracket type t, and depth d, independent of everything else like position.
Required balance condition (Both necessary and sufficient). Balanced != Interpretable, uniform attention is balanced, can also learn the Dyck grammar, but it does not reflect the task structure.
Balanced is weak constraint, still have diverse attention pattern. Balance condition can improve OOD => Intuition: Optimal models should be belanced.
Weight Matrix: TF can be approximated by a non-strucutral pruning of logarithmically larger of TF w.h.p. Proof sketch: Lottery ticket hypothesis (Approximate MLP by random networks). “Curse” of large models: Use large models may hide the interpretable patterns.
Look at activations instead of weights, use linear probing.
Negative Result by Danqi Chen: 4-dim model dyck. More interpretable model is worse in generalization. (Illusion of interpretability) https://arxiv.org/abs/2312.03656
Construction: [2303.08117] Do Transformers Parse while Predicting the Masked Word?
FLANN Seminar (Oct 13th 2025)
https://arxiv.org/pdf/2508.12837
Loss Landscap while training TF on sequences from a synthetic language model. Empirical training: stage-wise transitions.
Plateau: Learns a induction head / Acquires syntax at plateau / partial solution.
n-gram language model.
In-context population loss (CE on next token).
Construct the two-layer TF to implement k-gram estimator. First attn layer creates (k-1)-history, second layer matches the (k-1)-history and aggregates the following token. With this construction, we can show gradient of CE loss function vanishes, which partly explains the loss plateau behavior.
FLANN Seminar (Oct 20th 2025)
Topic: Language Identification, Generation, and Hallucination Detection in the limit.
Language Generation (Kleinberg, Mulliainathan 2024): Guess strings inside the language A but not in the “training set”. Algo never sees negative examples, no feedback. Assume all languages are infinite.
Thm: Language generation in the limit is possible for any countable collection of languages. (identification is impossible)
e.g.: After seeing many C programs Generation: Output valid C programs Identification: Output valid grammar for C (Is hard, by a lower bound construction)
Validity vs breadth tradeoff (hallucination vs mode-collapse).
Critical language.